




In unseren vorherigen Blog-Posts haben wir die Theorie hinter der Entwicklung wartbarer Software erkundet. Wir begannen mit einem Blick auf Die vielschichtigen Probleme der Softwareentwicklung, wo wir häufige Probleme wie Code-Duplikation, enge Kopplung und Skalierungsprobleme identifizierten, die Software schwer wartbar machen. Dann stellten wir Clean Architecture: Ein tiefer Einblick in strukturiertes Software-Design, vor und erklärten, wie dieses Pattern uns dabei hilft, Belange zu trennen und Dependencies effektiv zu verwalten.
Wir setzten fort, indem wir Wie Clean Architecture häufige Herausforderungen bei der Softwareentwicklung löst, untersuchten und die praktischen Vorteile einer geschichteten Architektur aufzeigten. Schließlich behandelten wir MVVM als komplementäres Muster für Clean Architecture-Anwendungen, und erklärten, warum das Model-View-ViewModel-Pattern gut als Präsentationsschicht innerhalb von Clean Architecture funktioniert.
Falls Clean Architecture oder MVVM-Konzepte für Sie neu sind, empfehlen wir Ihnen, diese Posts zuerst zu lesen.
Sie bieten die theoretischen Grundlagen, die diese praktische Implementierung leichter verständlich machen.
Jetzt schauen wir uns diese Konzepte in Aktion an.
Dieser Post zeigt Ihnen, wie Sie eine echte React-Anwendung mit Clean Architecture-Prinzipien und dem MVVM-Pattern entwickeln. Wir erstellen eine To-do-Anwendung, die demonstriert, wie sich Theorie in funktionierenden Code übersetzt. Außerdem lernen Sie, wie Sie Ihre React-App in Schichten strukturieren, MVVM mit React Hooks und Komponenten implementieren und Dependency Injection verwenden, um das Dependency Inversion Principle zu befolgen.
Die Beispiel-Anwendung stammt aus meinem Vortrag auf der code.talks Konferenz 2023, wo ich diese Konzepte präsentierte. Sie können sich die Präsentation auf YouTube ansehen, falls Sie daran interessiert sind, die Konzepte noch detaillierter erklärt zu bekommen.
Am Ende dieses Blog-Posts werden Sie eine praktische Vorlage für die Entwicklung von React-Anwendungen haben, die leichter zu warten, zu testen und zu erweitern sind. Den kompletten Quellcode finden Sie in unserem GitHub-Repository.
Beispiel To-do-App
Jetzt setzen wir Theorie in die Praxis um. Wir erstellen eine einfache To-do-Anwendung, die demonstriert, wie Clean Architecture und MVVM in einem echten React-Projekt zusammenarbeiten.
Seien wir ehrlich: Eine To-do-Anwendung ist wahrscheinlich nicht das beste reale Beispiel, um Clean Architecture und MVVM zu demonstrieren. In der Praxis würden Sie niemals eine so komplexe Architektur für eine einfache CRUD-Anwendung wie diese erstellen. Der Overhead wäre für etwas so Unkompliziertes völlig ungerechtfertigt.
Warum also eine To-do-App verwenden? Obwohl architektonisch überdimensioniert, funktioniert sie gut als Lernbeispiel, weil sie leicht zu verstehen ist und alle wesentlichen Operationen (Erstellen, Lesen, Aktualisieren, Löschen) enthält, ohne sich in komplexer Geschäftslogik zu verlieren. Der echte Wert von Clean Architecture wird bei komplexeren Szenarien deutlich: Anwendungen mit mehreren Benutzertypen, die unterschiedliche Berechtigungen benötigen, Systeme, die sich in mehrere externe APIs integrieren müssen, oder Projekte bei denen sich Geschäftsregeln häufig ändern und mehrere Teile der Anwendung betreffen.
Betrachten Sie dies als Trainingsgrundlage, die die Patterns klar demonstriert. Denken Sie daran, dass der Komplexitäts-Trade-off, den wir in unserem vorherigen Post behandelt haben, hier absolut zutrifft. Für eine echte To-do-App würde ein einfacherer Ansatz viel mehr Sinn machen.
Im weiteren Verlauf zeige ich Ihnen Auszüge der wichtigsten Komponenten. Die komplette Implementierung mit allen Dateien finden Sie in unserem GitHub-Repository.
Features
Unsere To-do-Anwendung deckt die Kernoperationen ab, die Sie in den meisten Anwendungen benötigen:
- Read: Eine Liste aller To-dos abrufen
- Create: Ein neues To-do mit Titel und Beschreibung hinzufügen
- Update: Ein vorhandenes To-do bearbeiten
- Delete: Ein To-do aus der Liste entfernen
Diese Operationen mögen grundlegend erscheinen, aber sie repräsentieren das Fundament des Datenmanagements in jeder Anwendung, von einfachen Tools bis hin zu komplexen Unternehmenssystemen.
UI
Unsere Anwendung besteht aus drei Hauptansichten, die den kompletten To-do-Workflow abdecken. Schauen wir uns die Wireframes an, um die User Journey zu verstehen:
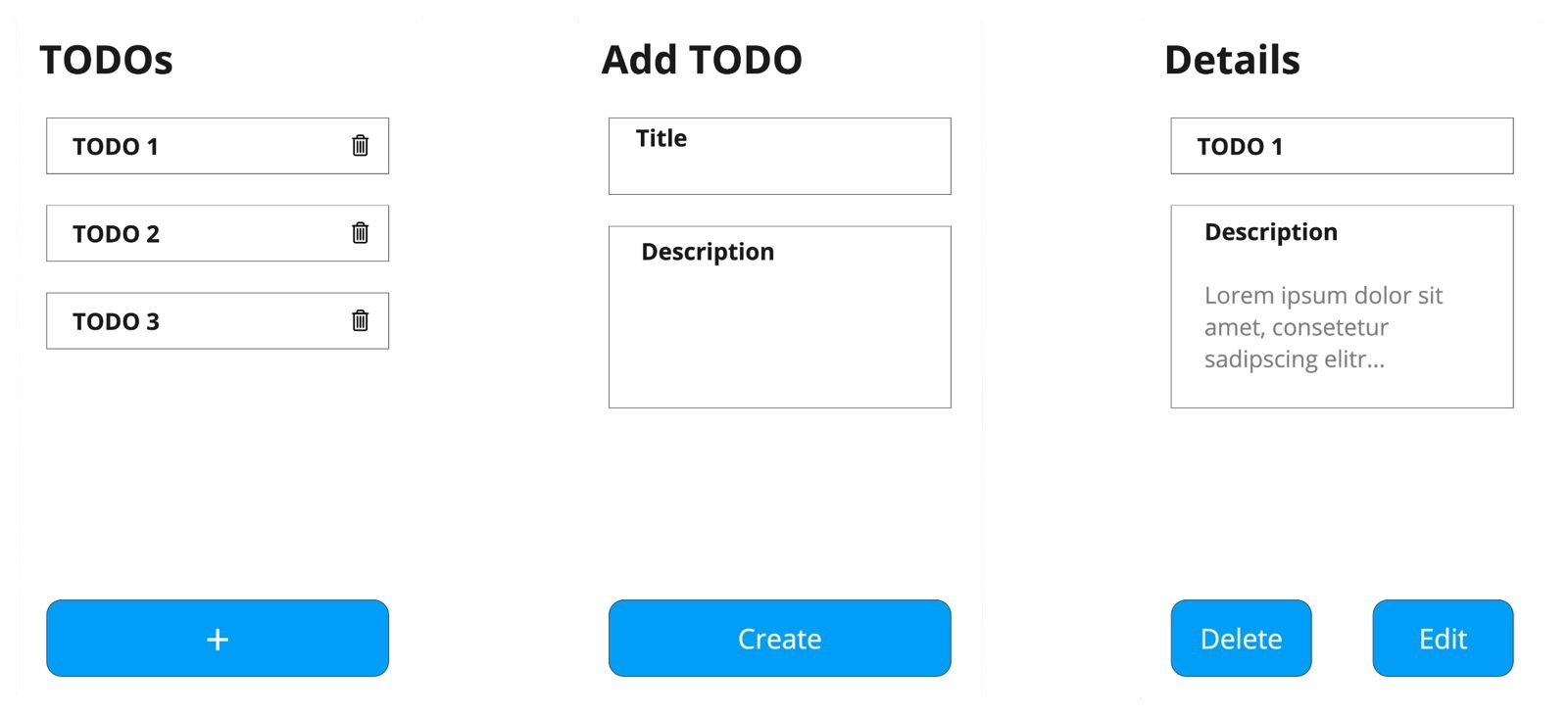
1. To-do-Ansicht
Dies ist der Hauptbildschirm, den die Nutzer sehen, wenn sie die Anwendung öffnen. Er zeigt alle verfügbaren To-dos in einem Listenformat mit einem „+“-Button am unteren Rand zum Erstellen neuer Einträge an. Jeder To-do-Eintrag enthält ein Papierkorb-Symbol für schnelles Löschen, ohne die Detailansicht öffnen zu müssen.
2. To-do hinzufügen-Ansicht
Wenn Nutzer auf den „+“-Button klicken, navigieren sie zu dieser Ansicht, wo sie ein neues To-do erstellen können. Das Formular enthält Felder für Titel und Beschreibung. Nach dem Ausfüllen der Details und Klicken auf „Erstellen“ kehren die Nutzer zur Haupt-To-dos-Ansicht zurück, wobei ihr neuer Eintrag hinzugefügt wurde.
3. Detailansicht
Ein Klick auf einen beliebigen To-do-Eintrag führt die Nutzer zu dieser detaillierten Ansicht, die den vollständigen Titel und die Beschreibung zeigt. Hier können Nutzer den Inhalt direkt bearbeiten oder das To-do löschen. Sowohl „Bearbeiten“- als auch „Löschen“-Aktionen führen die Nutzer zur Haupt-To-dos-Ansicht zurück.
Zusammenfassung des User Flows:
- Schnelles löschen: Nutzer können Einträge direkt aus der Liste über Papierkorb-Symbole löschen.
- Erstellungs-Flow: Nutzer navigieren von der Hauptansicht zur Hinzufügen-Ansicht und kehren dann nach dem Erstellen eines To-dos zur Hauptansicht zurück.
- Bearbeitungs-Flow: Nutzer gehen von der Hauptansicht zur Details-Ansicht zum Bearbeiten und kehren dann zur Hauptansicht zurück.
- Detailliertes Löschen: Nutzer können Einträge auch löschen, indem sie zur Details-Ansicht navigieren und dann zur Hauptansicht zurückkehren.
Diese einfache Drei-Ansichten-Struktur deckt alle CRUD-Operationen ab und hält die Benutzererfahrung dennoch unkompliziert und intuitiv.
Zuordnung zu den Clean Architecture Schichten
Nachdem wir nun wissen, was unsere Anwendung macht, ordnen wir ihre Komponenten den Clean Architecture Schichten zu. Dieser Schritt ist entscheidend, weil er zeigt, wie theoretische Konzepte in eine echte Code-Struktur übertragen werden.
Wie wir in Clean Architecture: Ein tiefer Einblick in strukturiertes Software-Design, erkundet haben, besteht Clean Architecture aus vier Schichten, wobei die innerste am abstraktesten und die äußerste am spezifischsten und am häufigsten verändert wird. Die detaillierte Struktur und Verantwortlichkeiten jeder Schicht werden in diesem Post erklärt.
Schauen wir uns Uncle Bobs ursprüngliches Clean Architecture-Diagramm an, um zu visualisieren, wie unsere Anwendungskomponenten in diese Struktur passen:
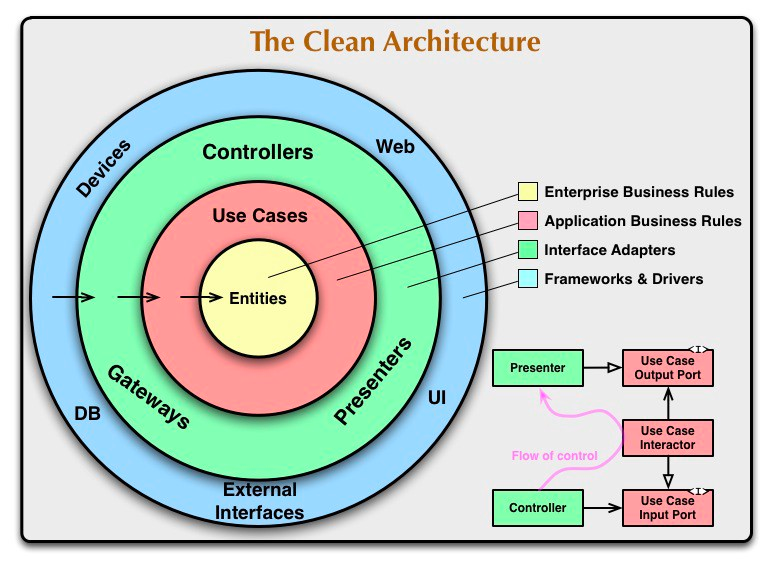
So ordnen sich unsere To-do-Anwendungskomponenten den einzelnen Schichten zu:
Entities (Enterprise Business Rules)
- Todo - Unsere zentrale Geschäftsentität, die eine Aufgabe repräsentiert
- ITodoRepository interface - Definiert, welche Datenoperationen die Domain benötigt
Use Cases (Application Business Rules)
- Get Todos Use Case - Ruft alle To-dos ab
- Get Todo Use Case - Ruft ein spezifisches To-do ab
- Create Todo Use Case - Erstellt ein neues To-do
- Update Todo Use Case - Aktualisiert ein vorhandenes To-do
- Delete Todo Use Case - Entfernt ein To-do
Interface Adapters
- ViewModels (fungieren als Presenter):
- Todo List ViewModel
- Create Todo ViewModel
- Todo Details ViewModel
- Todo Repository Implementation - Implementiert das ITodoRepository-Interface
Frameworks & Drivers
- React Views (UI Komponenten):
- TodoList.tsx
- CreateTodo.tsx
- TodoDetails.tsx
- Awilix DI Container - Dependency injection framework
- React Router - Navigations-Framework
Warum diese Zuordnung wichtig ist:
Das Schlüsselprinzip ist, dass Dependencies nach innen fließen. Use Cases hängen vom Repository-Interface (das in der Domain definiert ist) ab, nicht von der Implementierung. Die Repository-Implementierung hängt von der Datenquelle ab. Dies schafft ein System, in dem Geschäftslogik unabhängig von UI-Frameworks, Datenbanken oder externen APIs bleibt.
Technischer Hinweis:
Beachten Sie, wie das Repository-Interface in der Domain-Schicht lebt, während seine Implementierung in der Interface Adapters-Schicht liegt. Dies folgt dem Dependency Inversion Principle - Module hoher Ebene (Use Cases) hängen von Abstraktionen (ITodoRepository) ab, nicht von konkreten Implementierungen.
Sie können React gegen Angular austauschen oder Local Storage gegen eine REST API, ohne Ihre Kern-Geschäftsregeln oder Use Cases zu beeinträchtigen. Genau das ist die Stärke von Clean Architecture.
Application Flow
Bevor wir uns in den Code vertiefen, schauen wir uns an, wie Daten durch unsere Anwendung fließen. Dieser Flow demonstriert, wie Clean Architecture und MVVM zusammenarbeiten, um eine klare Trennung der Belange zu schaffen.
Verfolgen wir eine typische Benutzerinteraktion am Beispiel der Todo Details View:
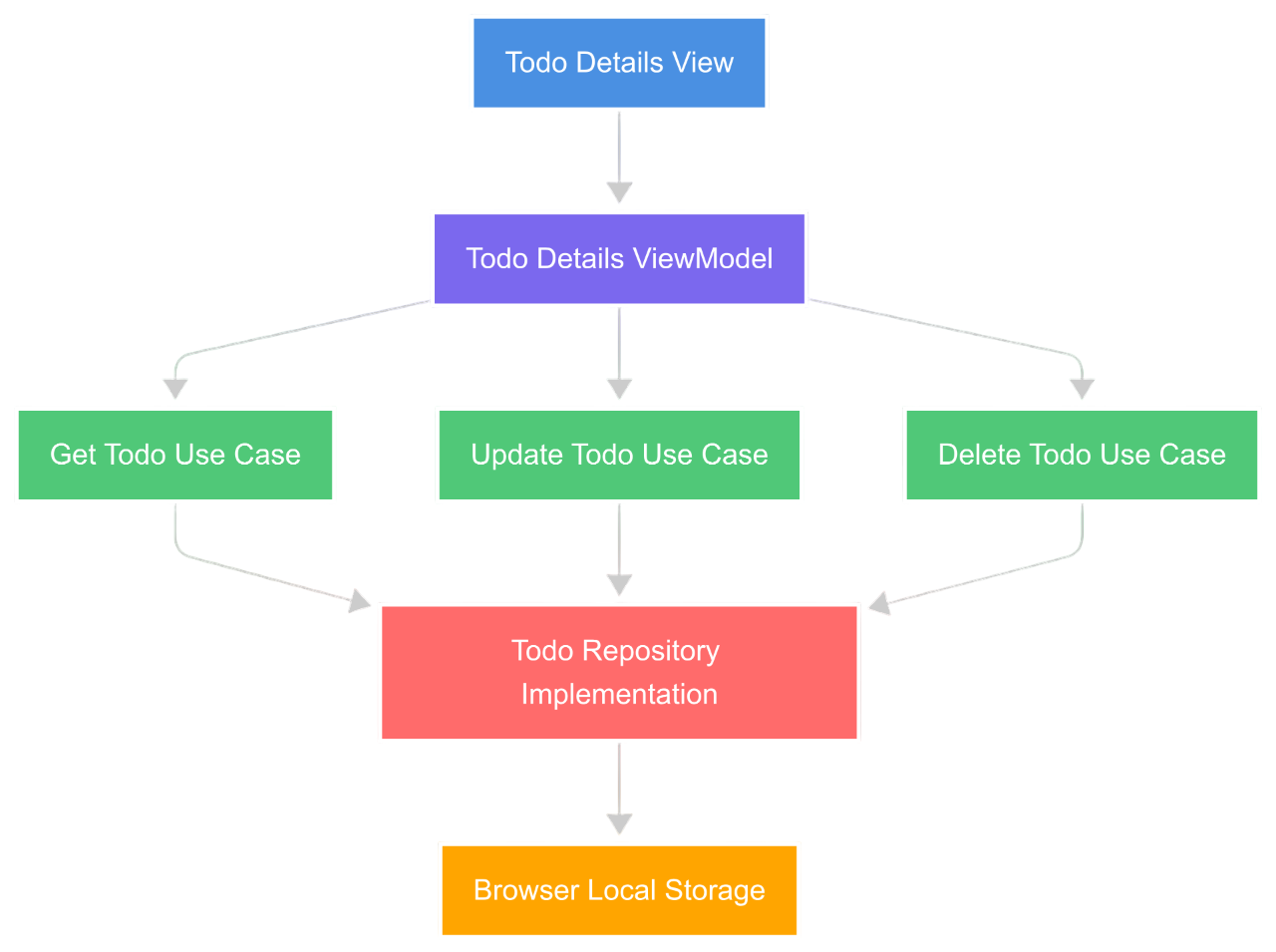
So funktioniert der Flow:
- Benutzerinteraktion: Der Benutzer interagiert mit der Todo Details View (Klicken auf Bearbeiten, Löschen oder Anzeigen von Details)
- ViewModel-Verarbeitung: Die View übergibt die Benutzeraktion an das Todo Details ViewModel, das bestimmt, welcher Use Case ausgeführt werden soll
- Use Case-Ausführung: Das ViewModel ruft den entsprechenden Use Case auf:
- Get Todo Use Case - Ruft ein spezifisches To-do zur Anzeige ab
- Update Todo Use Case - Aktualisiert ein vorhandenes To-do mit neuen Daten
- Delete Todo Use Case - Entfernt ein To-do aus dem System
- Repository-Zugriff: Alle Use Cases interagieren mit dem To-do Repository, um ihre Operationen durchzuführen
- Datenpersistierung: Das Repository handhabt direkt die Local Storage-Operationen des Browsers, um die tatsächlichen Daten abzurufen, zu speichern oder zu löschen
Warum dieser Flow wichtig ist:
Diese Struktur stellt sicher, dass jede Schicht eine einzige Verantwortung hat. Die View handhabt UI-Rendering und leitet Benutzerinteraktionen an das ViewModel weiter, das ViewModel verwaltet Präsentationslogik, Use Cases enthalten Geschäftsregeln und das Repository handhabt Datenzugriff. Diese Trennung macht den Code einfacher zu testen, zu warten und zu modifizieren.
Das gleiche Flow-Pattern gilt für alle anderen Views in unserer Anwendung - Todo List View und Create Todo View folgen identischen Mustern mit ihren jeweiligen ViewModels und Use Cases.
Projektstruktur
Nachdem wir den übergeordneten Application Flow gesehen haben, schauen wir uns die Projektstruktur an und gehen die wichtigsten Ordner einzeln durch.
├── README.md
├── package.json
├── vite.config.ts
├── src
│ ├── adapter # implements domain contracts
│ │ └── repository
│ │ └── todoRepository.ts
│ ├── di # Awilix container & registrations
│ │ └── container.ts
│ ├── domain # enterprise & application business rules
│ │ ├── model
│ │ │ └── types
│ │ │ └── Todo.ts
│ │ ├── repository
│ │ │ └── ITodoRepository.ts
│ │ └── useCases
│ │ └── todo
│ │ ├── createTodoUseCase.ts
│ │ ├── deleteTodoUseCase.ts
│ │ ├── getTodoUseCase.ts
│ │ ├── getTodosUseCase.ts
│ │ └── updateTodoUseCase.ts
│ ├── presenter # React-specific presentation layer
│ │ ├── components
│ │ │ ├── atoms
│ │ │ └── molecules
│ │ └── pages
│ │ ├── CreateTodo
│ │ │ └── …
│ │ ├── TodoDetails
│ │ │ └── …
│ │ └── TodoList
│ │ ├── TodoList.tsx
│ │ └── todoListViewModel.ts
│ ├── App.tsx # root component
│ └── main.tsx # application bootstrap
└── tsconfig.jsonWie sich die Ordner den Clean Architecture-Schichten zuordnen:
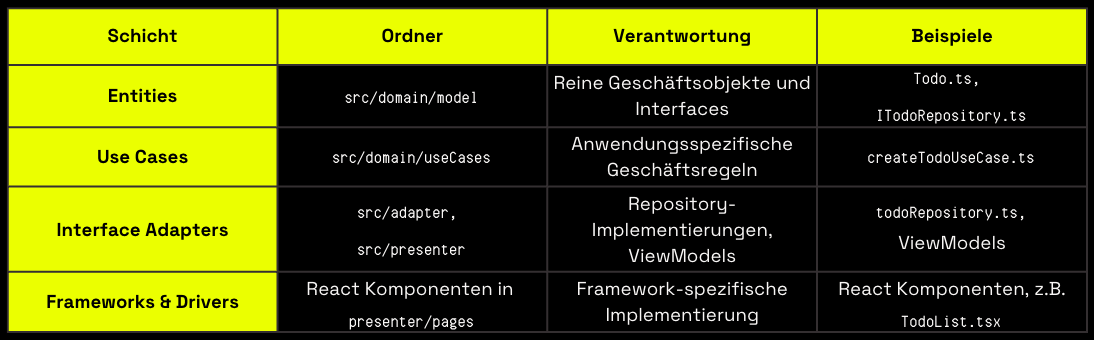
Wie Sie der obigen Tabelle entnehmen können, entspricht unsere Ordnerstruktur eindeutig den Schichten der Clean Architecture, wobei die Abhängigkeiten von den äußeren Ordnern (Presenter) zu den inneren Ordnern (Domain) verlaufen.
Sehen wir uns nun an, wie diese Schichten in der Praxis tatsächlich miteinander verbunden sind.
Ein kurzer Blick auf den DI Container
So verbindet der Dependency Injection Container alle diese Komponenten:
export const DI = createContainer();
DI.register({
// repository
todoRepository: asFunction(todoRepository),
// use cases
createTodoUseCase: asFunction(createTodoUseCase),
deleteTodoUseCase: asFunction(deleteTodoUseCase),
getTodoUseCase: asFunction(getTodoUseCase),
getTodosUseCase: asFunction(getTodosUseCase),
updateTodoUseCase: asFunction(updateTodoUseCase),
// view-models
todoListViewModel: asFunction(createTodoListViewModel),
todoDetailsViewModel: asFunction(createTodoDetailsViewModel),
createTodoViewModel: asFunction(createCreateTodoViewModel),
});Den Dependency Injection Container verstehen
Wenn Sie sich den obigen Code anschauen, können Sie sehen, wie wir verschiedene Komponenten mit spezifischen Methoden registrieren:
asFunction()für Factory-Funktionen, die Komponenten wietodoRepositoryund Use Cases erstellen- Jede Registrierung hat einen Namen (wie
"todoRepository","getTodosUseCase"), den wir verwenden, um Dependencies in unserer gesamten Anwendung aufzulösen
Die Vorteile dieses Ansatzes:
-
Inversion of Control – Anstatt dass Komponenten ihre eigenen Dependencies erstellen, stellt der Container sie automatisch bereit. Wenn wir beispielsweise
"todoListViewModel", auflösen, erstellt der Container es automatisch mit den erforderlichen Use Cases (getTodosUseCase,deleteTodoUseCase) bereits injiziert. Dies folgt dem Dependency Inversion Principle, das wir in Clean Architecture: Ein tiefer Einblick in strukturiertes Software-Design behandelt haben, wo Module hoher Ebene von Abstraktionen abhängen, nicht von konkreten Implementierungen. -
Testbarkeit – In Unit-Tests können Sie diese Registrierungen durch Mock-Implementierungen ersetzen. Anstatt beispielsweise das echte
todoRepository, zu registrieren, registrieren Sie eine Testversion, die vorhersagbare Daten zurückgibt. Dies ermöglicht es Ihnen, jede Komponente isoliert zu testen, ohne von echten Storage-Operationen oder externen Services abhängig zu sein. -
Flexibilität – Müssen Sie von Local Storage zu einer API oder Datenbank wechseln? Erstellen Sie eine neue Repository-Implementierung und ändern Sie die
todoRepositoryRegistrierung. Der Rest Ihrer Anwendung bleibt unverändert, weil er vomITodoRepositoryInterface abhängt, nicht von der konkreten Implementierung.
Nun wo Ordnerlayout und Dependency-Verkabelung geklärt sind, können wir uns auf einen konkreten Code-Ausschnitt konzentrieren. Im folgenden Abschnitt werden wir das 'TodoList' View / ViewModel-Paar untersuchen, um zu sehen, wie die Präsentationsschicht die Use Cases konsumiert und UI-Logik von Geschäftsregeln getrennt hält.
TodoList View / ViewModel Implementierung
Schauen wir uns eine konkrete Implementierung des MVVM-Patterns in unserer React-Anwendung an. Das TodoList View und ViewModel Paar demonstriert, wie die Präsentationsschicht Use Cases konsumiert und dabei UI-Logik von Geschäftsregeln getrennt hält.
Die TodoList View
Die View-Komponente ist verantwortlich für das Rendern der UI und die Weiterleitung von Benutzerinteraktionen an das ViewModel:
import { FC } from 'react'
import { useNavigate } from 'react-router-dom'
import { DI } from '../../../di/ioc.ts'
export const TodoList: FC = () => {
const navigate = useNavigate()
const { todos, deleteTodo, showDeleteDialog, closeDeleteDialog, todoToDelete } = DI.resolve('todoListViewModel')
return (
<>
<Page
headline="TODOs"
footer={<Button customStyles={styles.button} label="+" onClick={() => navigate('/todo/create')} />}>
<List
items={todos}
onItemClick={todo => navigate(`/todo/detail/${todo.id}`)}
onItemDelete={showDeleteDialog} />
</Page>
{todoToDelete !== undefined && (
<DeleteTodoDialog
open={true}
todoName={todoToDelete.title}
onConfirm={deleteTodo}
onCancel={closeDeleteDialog} />
)}
</>
)
}Was die View macht:
- Dependency Resolution: Verwendet
DI.resolve('todoListViewModel'), um die ViewModel-Instanz mit allen erforderlichen Dependencies injiziert zu erhalten - UI Rendering: Rendert die Seitenstruktur mit einer Überschrift, der To-do-Liste und einem Hinzufügen-Button
- Navigation Handling: Verwaltet das Routing zu Create- und Detail-Views mit React Routers
useNavigate - Event Forwarding: Leitet Benutzerinteraktionen an das ViewModel weiter, ohne Geschäftslogik zu enthalten
- Conditional Rendering: Zeigt den Löschbestätigungsdialog basierend auf dem ViewModel-Zustand an
Beachten Sie, dass die View passiv bleibt. Sie zeigt Daten an und leitet Events weiter, enthält aber keine Geschäftslogik.
Das TodoList ViewModel
Das ViewModel handhabt Präsentationslogik und UI-State-Management und fungiert als Koordinationspunkt zwischen unserer React View und den Use Cases der Domain:
import { useEffect, useState } from 'react'
import { Todo } from '../../../domain/model/Todo.ts'
import { Id, UseCase, UseCaseWithParams } from '../../../domain/model/types'
type Dependencies = {
readonly getTodosUseCase: UseCase<Todo[]>
readonly deleteTodoUseCase: UseCaseWithParams<void, Id>
}
export const todoListViewModel = ({ getTodosUseCase, deleteTodoUseCase }: Dependencies) => {
const [todoToDelete, setTodoToDelete] = useState<Todo>()
const [todos, setTodos] = useState<Todo[]>([])
const showDeleteDialog = (todo: Todo) => setTodoToDelete(todo)
const closeDeleteDialog = () => setTodoToDelete(undefined)
const getTodos = async () => {
const result = await getTodosUseCase.execute()
setTodos(result)
}
const deleteTodo = async () => {
if (todoToDelete !== undefined) {
await deleteTodoUseCase.execute(todoToDelete.id)
setTodos(todos.filter(todo => todo.id !== todoToDelete.id))
closeDeleteDialog()
}
}
const sortById = (prevTodo: Todo, todo: Todo) => prevTodo.id < todo.id ? -1 : prevTodo.id > todo.id ? 1 : 0
useEffect(() => {
void getTodos()
}, [])
return { todos: todos.sort(sortById), deleteTodo, showDeleteDialog, closeDeleteDialog, todoToDelete }
}Was das ViewModel macht:
- Dependency Injection Pattern: Erhält seine Dependencies als Parameter in der Funktionssignatur und folgt damit dem Dependency Inversion Principle aus unseren Clean Architecture-Posts - das ViewModel hängt von Abstraktionen (Use Case Interfaces) ab, nicht von konkreten Implementierungen.
- Local State Management: Verwaltet zwei Teile des lokalen State mit Reacts
useStateHook:todos: Hält die aktuelle To-do-Liste für die AnzeigetodoToDelete: Verfolgt, welches To-do zum Löschen vorgemerkt ist (für den Bestätigungsdialog)
- Use Case Orchestration: Koordiniert zwischen der View und den Domain Use Cases:
getTodos(): Führt dengetTodosUseCaseaus und aktualisiert den lokalen StatedeleteTodo(): Führt dendeleteTodoUseCaseaus und aktualisiert die UI
- Präsentationslogik: Enthält UI-spezifische Logik, die nicht in die Domain gehört:
sortById: Stellt sicher, dass To-dos immer in konsistenter Reihenfolge angezeigt werden- Dialog state management:
showDeleteDialogundcloseDeleteDialog
- Lifecycle Management: Der
useEffectHook initialisiert den Komponentenzustand, wenn die View gemountet wird, und lädt automatisch To-dos ohne Dependency-Trigger.
ViewModels im Clean Architecture-Kontext
Diese ViewModel-Implementierung demonstriert die Interface Adapters-Schicht in Aktion: Sie übersetzt zwischen Domain Use Cases und React-Komponenten und verwaltet dabei Präsentationszustand. Da das ViewModel seine Dependencies als Parameter erhält, können Sie es einfach isoliert testen, indem Sie Mock Use Cases injizieren.
Dieser Ansatz stellt sicher, dass unsere Präsentationslogik sauber, testbar und unabhängig sowohl vom UI-Framework als auch von der Geschäftsdomäne bleibt.
Use Cases
Unser ViewModel hängt von Use Cases ab, um Geschäftsoperationen auszuführen. Schauen wir uns an, wie diese Use Cases funktionieren.
Type Definitions
Zuerst schauen wir uns die Typen an, die sicherstellen, dass unsere Use Cases einem konsistenten Muster folgen:
export type Id = string
export type UseCase<Result> = {
readonly execute: () => Promise<Result>
}
export type UseCaseWithParams<Result, Params> = {
readonly execute: (params: Params) => Promise<Result>
}Diese Typen bieten einen konsistenten Vertrag für alle Use Cases in unserer Anwendung. Jeder Use Case muss eine execute-Methode implementieren, die ein Promise zurückgibt, wodurch asynchrone Operationen ordnungsgemäß behandelt werden.
Get Todos Use Case
Dieser Use Case behandelt das Abrufen aller To-dos aus unserem System. Er ist die Grundlage für die Anzeige der To-do-Liste in unserer Anwendung und wird aufgerufen, wann immer wir die To-do-Daten aktualisieren oder initial laden müssen.
import { Todo } from '../../model/Todo.ts'
import { UseCase } from '../../model/types'
import { ITodoRepository } from '../../repository/ITodoRepository.ts'
type Dependencies = {
readonly todoRepository: ITodoRepository
}
export const getTodosUseCase = ({ todoRepository }: Dependencies): UseCase<Todo[]> => ({
execute: () => todoRepository.get(),
})Delete Todo Use Case
Dieser Use Case verwaltet das Löschen eines spezifischen To-do-Elements. Er wird ausgelöst, wenn Benutzer ein To-do entweder aus der Hauptlistenansicht oder aus der detaillierten To-do-Ansicht entfernen möchten.
import { Id, UseCaseWithParams } from '../../model/types'
import { ITodoRepository } from '../../repository/ITodoRepository.ts'
type Dependencies = {
readonly todoRepository: ITodoRepository
}
export const deleteTodoUseCase = ({ todoRepository }: Dependencies): UseCaseWithParams<void, Id> => ({
execute: (id: Id) => todoRepository.delete(id),
})Was die Use Cases machen:
- Dependency Injection: Beide Use Cases erhalten ihre Dependencies als Parameter in der Funktionssignatur und folgen damit dem Dependency Inversion Principle. Sie hängen vom
ITodoRepositoryInterface ab, nicht von einer konkreten Implementierung. - Type Safety: Die Use Cases implementieren spezifische Type-Verträge:
getTodosUseCase: GibtUseCase<Todo[]>zurück - ein Use Case, der ein Array von To-dos zurückgibtdeleteTodoUseCase: GibtUseCaseWithParams<void, Id>zurück - ein Use Case, der einen ID-Parameter nimmt und void zurückgibt
- Business Logic Orchestration: Obwohl diese Beispiele einfach sind, koordinieren Use Cases Geschäftsoperationen. Der
getTodosUseCaseruft alle To-dos ab, währenddeleteTodoUseCaserein spezifisches To-do anhand der ID entfernt. - Repository Abstraction: Beide Use Cases interagieren mit dem
ITodoRepositoryInterface und stellen sicher, dass sie unabhängig von Datenquellen-Implementierungsdetails bleiben. - Asynchrone Operationen: Alle Use Cases geben Promises zurück und sind damit bereit für asynchrone Operationen wie API-Aufrufe oder Datenbanktransaktionen.
Use Cases jenseits von CRUD
Die obigen Beispiele könnten Use Cases wie einfache CRUD-Wrapper erscheinen lassen, aber das liegt nur daran, dass unsere To-do-App bewusst grundlegend ist. In echten Anwendungen handhaben Use Cases anspruchsvollere Geschäftsoperationen, die sich über mehrere Repositories erstrecken und komplexe Logik enthalten können.
Schauen wir uns einige Beispiele von Use Cases an, die für die Behandlung komplexerer Operationen verantwortlich sind:
1. Entitäten-übergreifende Operationen
Dieser Use Case demonstriert, wie Geschäftsoperationen oft mehrere Entities umfassen. Beim Veröffentlichen eines Artikels müssen wir Benutzerberechtigungen validieren, den Artikelstatus aktualisieren und Abonnenten benachrichtigen. Das sind Operationen, die verschiedene Teile unserer Domain berühren.
const publishArticleUseCase = ({
articleRepository,
userRepository,
notificationRepository
}: Dependencies) => ({
execute: async (articleId: Id, authorId: Id) => {
// Check if author has permissions
const author = await userRepository.getById(authorId)
if (!author.canPublish) {
throw new Error('Insufficient permissions')
}
// Update article status
const article = await articleRepository.getById(articleId)
const publishedArticle = await articleRepository.update(articleId, {
...article,
status: 'published',
publishedAt: new Date()
})
// Notify subscribers
await notificationRepository.notifySubscribers(authorId, publishedArticle)
return publishedArticle
}
})2. Koordination zwischen mehreren Repositories
Komplexe Anwendungen müssen oft Daten aus mehreren Quellen aggregieren, um aussagekräftige Erkenntnisse zu schaffen. Dieser Use Case zeigt, wie man zwischen verschiedenen Repositories koordiniert und dabei Geschäftslogik auf die kombinierten Daten anwendet.
const generateUserDashboardUseCase = ({
userRepository,
projectRepository,
analyticsRepository
}: Dependencies) => ({
execute: async (userId: Id) => {
// Fetch user data
const user = await userRepository.getById(userId)
// Get user's projects
const projects = await projectRepository.getByUserId(userId)
// Calculate analytics across all projects
const analytics = await analyticsRepository.getProjectAnalytics(
projects.map(project => project.id)
)
// Business logic: determine user's productivity score
const productivityScore = calculateProductivityScore(projects, analytics)
return {
user,
projects,
analytics,
productivityScore,
recommendations: generateRecommendations(user, productivityScore)
}
}
})3. Komplexe Businesslogik
Echte Geschäftsprozesse beinhalten mehrere Validierungsschritte, Berechnungen und Koordination zwischen Systemen. Dieser Bestellverarbeitungs-Use Case demonstriert, wie Use Cases mehrstufige Workflows mit Geschäftsregeln und Fehlerbehandlung handhaben.
const processOrderUseCase = ({
orderRepository,
inventoryRepository,
paymentRepository,
customerRepository
}: Dependencies) => ({
execute: async (orderData: OrderData) => {
// Validate customer eligibility
const customer = await customerRepository.getById(orderData.customerId)
if (customer.status !== 'active') {
throw new Error('Customer account inactive')
}
// Check inventory and reserve items
const reservations = await Promise.all(
orderData.items.map(item =>
inventoryRepository.reserveItem(item.productId, item.quantity)
)
)
// Calculate pricing with business rules
const pricing = calculateOrderPricing(orderData.items, customer.tier)
// Process payment
const payment = await paymentRepository.processPayment(
customer.paymentMethod,
pricing.total
)
// Create order
const order = await orderRepository.create({
...orderData,
pricing,
paymentId: payment.id,
status: 'confirmed'
})
return { order, payment, reservations }
}
})Was diese Use Cases wertvoll macht
- Zentralisierung der Geschäftslogik: Use Cases werden zum einzigen Ort, wo komplexe Geschäftsregeln leben, wodurch sie einfacher zu warten und zu testen sind.
- Cross-Cutting Concerns: Sie handhaben Operationen, die mehrere Entitäten und Repositories umfassen - etwas, was einzelne Repositories nicht leisten können.
- Transaktionsähnliche Abläufe: Use Cases können mehrstufige Operationen koordinieren und Konsistenz über verschiedene Datenquellen sicherstellen.
- Domänenwissen: Sie kodieren die spezifischen Geschäftsprozesse und Workflows, die Ihre Anwendung wertvoll machen.
Real-World Szenarien, in denen Use Cases glänzen
Hier sind einige häufige Szenarien, in denen Use Cases echten architektonischen Wert bieten. Das sind nur wenige Beispiele - Sie werden feststellen, dass Use Cases unverzichtbar werden, wann immer Ihre Anwendung komplexe Geschäfts-Workflows, mehrstufige Operationen oder Koordination zwischen verschiedenen Teilen Ihres Systems beinhaltet:
- E-Commerce-Bestellabwicklung: Inventarprüfungen, Zahlungsabwicklung, Kundenvalidierung, Versandberechnungen
- Content Management: Publishing-Workflows, die Inhaltsvalidierung, Benutzerberechtigungen und Benachrichtigungssysteme beinhalten
- User Onboarding: Kontoerstellung, Berechtigungssetup, Willkommens-E-Mails, initiale Datenpopulation
- Reporting und Analytics: Datenaggregation aus mehreren Quellen, komplexe Berechnungen, Caching-Strategien
- Integration Workflows: Datensynchronisation zwischen internen Systemen und externen APIs
Use Cases im Clean Architecture-Kontext
Diese Use Cases demonstrieren die Application Business Rules-Schicht in Clean Architecture. Sie enthalten anwendungsspezifische Logik und bleiben dabei unabhängig von externen Belangen wie Datenbanken, UI-Frameworks oder externen Services.
Denken Sie daran: Während unser To-do-Beispiel einfache Use Cases zur Klarstellung zeigt, wird das Pattern unschätzbar wertvoll beim Umgang mit komplexen Geschäftsoperationen, die Koordination zwischen mehreren Teilen Ihres Systems erfordern.
Repository
Das Repository führt die Aufrufe unserer Use Cases durch, um Datenoperationen auszuführen. Schauen wir uns unsere Repository-Implementierung an, die direkt die Local Storage-Operationen des Browsers handhabt.
import { Todo } from '../../domain/model/Todo.ts'
import { Id } from '../../domain/model/types'
import { ITodoRepository } from '../../domain/repository/ITodoRepository.ts'
export const todoRepository = (): ITodoRepository => {
const COLLECTION_NAME: string = 'todos'
const get = (): Promise<Todo[]> => {
try {
const result = localStorage.getItem(COLLECTION_NAME)
return result !== null ? JSON.parse(result) : []
} catch (error) {
return Promise.reject(error)
}
}
const getById = async (id: Id): Promise<Todo> => {
const todos = await get()
const todo = todos.find(({ id: todoId }) => todoId === id)
if (todo === undefined) {
throw Error(`Could not find todo with id ${id}`)
}
return todo
}
const create = async (title: string, description: string): Promise<Todo> => {
const todos = await get()
const id = `${Date.now()}`
const newTodo: Todo = { title, description, id }
localStorage.setItem(COLLECTION_NAME, JSON.stringify([...todos, newTodo]))
return newTodo
}
const update = async (id: Id, title: string, description: string): Promise<Todo> => {
const updatedTodo = { ...await getById(id), title, description }
const todos = (await get()).filter(({ id: todoId }) => todoId !== id)
localStorage.setItem(COLLECTION_NAME, JSON.stringify([...todos, updatedTodo]))
return updatedTodo
}
const deleteTodo = async (id: Id): Promise<void> => {
const todos = (await get()).filter(({ id: todoId }) => todoId !== id)
localStorage.setItem(COLLECTION_NAME, JSON.stringify(todos))
}
return { get, getById, create, update, delete: deleteTodo }
}Was das Repository macht:
- Direkte Implementierung: Das Repository enthält die localStorage-Implementierung und handhabt alle Datenpersistierungsoperationen direkt.
- CRUD-Operationen: Bietet alle grundlegenden Datenoperationen:
get(): Ruft alle To-dos aus localStorage ab, parst JSON oder gibt ein leeres Array zurückgetById(id): Findet ein spezifisches To-do anhand der ID und wirft einen Fehler, wenn es nicht gefunden wirdcreate(title, description): Generiert eine neue ID, erstellt das To-do und speichert es in localStorageupdate(id, title, description): Führt Updates mit vorhandenem To-do zusammen und speichertdelete(id): Filtert das angegebene To-do heraus und speichert die verbleibende Liste
- Fehlerbehandlung: Enthält Try-catch-Blöcke für localStorage-Operationen und aussagekräftige Fehlermeldungen.
- Interface-Implementierung: Implementiert das
ITodoRepositoryInterface, das in der Domain-Schicht definiert ist. - Asynchrone Operationen: Alle Methoden geben Promises zurück, um Konsistenz mit potenziellen Datenbankoperationen zu gewährleisten, obwohl localStorage synchron ist.
- Type Safety: Verwendet TypeScripts Utility-Typen, um Type Safety beim Erstellen und Aktualisieren von To-dos sicherzustellen.
Repository im Clean Architecture-Kontext
Dieses Repository demonstriert eine klare Implementierung der Interface Adapters-Schicht in Clean Architecture. Es enthält die localStorage-Implementierung und handhabt alle Datenpersistierungsoperationen direkt, während es vollständig von Geschäftslogik isoliert bleibt. Use Cases hängen von diesem Repository über das ITodoRepository-Interface ab, was es uns ermöglicht, Storage-Mechanismen einfach zu wechseln, ohne andere Schichten zu beeinträchtigen.
Dieser Ansatz stellt sicher, dass unsere Kern-Anwendungslogik unabhängig von Storage-Implementierungsdetails bleibt.
Die Vorteile dieses Patterns:
- Abstraktion: Use Cases hängen vom Repository-Interface ab, nicht von der konkreten Implementierung
- Flexibilität: Sie können einfach verschiedene Repository-Implementierungen erstellen (localStorage, REST API, Datenbank), ohne die Domain-Logik zu ändern
- Testbarkeit: Sie können Mock-Repository-Implementierungen für isolierte Tests von Use Cases injizieren
- Trennung der Belange: Das Repository handhabt Datenzugriffslogik, während Use Cases Geschäftslogik handhaben
In realen Anwendungen können Repositories zusätzliche Verantwortlichkeiten beinhalten, wie:
- Datenmapping: Konvertierung zwischen Persistierungsmodellen und Domain-Entities
- Fehlerbehandlung: Verwaltung von Datenzugriffsfehlern und Bereitstellung aussagekräftiger Fehlerantworten
- Caching: Performance-Optimierung durch Speicherung häufig verwendeter Daten
- Query-Optimierung: Handhabung komplexer Datenabrufmuster
Jedoch gehören Verantwortlichkeiten wie das Kombinieren von Daten aus mehreren Quellen oder Geschäftslogik-Transformationen in Use Cases, nicht in Repositories. Das Repository-Pattern sollte sich ausschließlich auf Datenzugriffsbelange konzentrieren, während Use Cases Orchestrierung und Geschäftslogik handhaben.
Das Pattern bleibt dasselbe - das Repository abstrahiert Datenzugriffsdetails von der Domain-Schicht, während es innerhalb seiner architektonischen Grenzen bleibt.
Fazit
In unseren vorherigen Blog-Posts haben wir die Theorie hinter Clean Architecture und MVVM erkundet. Nun haben wir gesehen, wie diese Konzepte in der Praxis funktionieren - von Entities und Use Cases bis hin zu ViewModels und Repositories.
Wie wir in unserem vorherigen Post thematisiert haben, erfordert Clean Architecture sorgfältige Überlegungen für kleinere Projekte. Unsere To-do-Anwendung demonstriert diese Patterns in einem vereinfachten Kontext und hilft Ihnen zu verstehen, wann und wie Sie sie auf Projekte anwenden, bei denen der Komplexitäts-Trade-off sinnvoll ist.
Diese Patterns bieten eine solide architektonische Grundlage. Während Skalierung immer eine durchdachte Implementierung erfordert, gibt Ihnen diese Struktur die Flexibilität, wachsende Komplexität zu bewältigen. Jede Schicht hat klare Verantwortlichkeiten, Dependencies fließen nach innen, und der Code bleibt testbar und wartbar.
Denken Sie daran: Während dieses To-do-Beispiel die Patterns klar demonstriert, beinhalten reale Anwendungen, die diese architektonische Komplexität rechtfertigen, normalerweise mehrere Benutzerrollen, Integrationen externer Systeme, komplexe Geschäftsregeln oder sich häufig ändernde Anforderungen. Das sind die Fälle, in denen Clean Architecture wirklich glänzt und einfachere Ansätze zu kurz greifen.
Sie finden die komplette Implementierung in unserem GitHub-Repository - verwenden Sie es als Ausgangspunkt für Ihre eigenen Projekte. Falls Sie diese Konzepte noch detaillierter erklärt sehen möchten, können Sie sich meine Präsentation von der code.talks-Konferenz 2023 ansehen.
Die Entwicklung wartbarer Software erfordert keine komplexen Frameworks oder komplizierten Patterns - sie erfordert durchdachte Architektur. Clean Architecture und MVVM bieten diese Struktur und helfen Ihnen dabei, Code zu schreiben, der Bestand hat.
